
一、可变数组
编写可变数组函数库
- 创建数组
- 回收数组
- 获取数组中单元个数
- 访问数组中的某个单元
- 增长数组长度

定义Array结构体:
定义为指针类型的结构体,似乎可以简化某些函数的调用传递参数,节省内存空间?
#ifndef ARRAY_H#define ARRAY_H
typedef struct{ int *array; int size;}*Array;
#endif但是,当我们在函数内部创建变量的时候,这个时候a指向的是已经存在的内存空间。
void test(){ Array a;}所以,一般情况下,定义结构体变量不要加*,不要定义指针类型
#ifndef ARRAY_H#define ARRAY_H
typedef struct{ int *array; int size;}Array;
Array array_create(int init_size);void array_free(Array *a);int array_size(const Array *a);int* array_at(Array *a,int index);void array_inflate(Array *a,int more_size);
#endif函数实现:
创建可变数组
思考:为什么不返回指针?
- 本地变量在函数使用后会销毁
Array array_create(int init_size){ Array a;//创建本地变量 a.size = init_size; a.array = (int*)malloc(sizeof(int)*a.size); return a;}释放数组空间
void array_free(Array *a){ free(a->array); a->array = Null;//防止重复调用,free(Null)是无害操作 a->size = 0;
}获取数组大小
思考:为什么不直接a.size获取大小?
- 目的:封装,保护了a的size,防止被修改,也利于后期维护
int array_size(const Array *a){ return a->size;}获取数组中对应元素的位置
思考:为什么要返回int类型指针而不直接返回int

- 使用
array_at(&a,0)取地址 - 使用
*array_at(&a,0)=10;可以直接进行赋值操作
当然,也可以重新编写array_set,array_get两个函数,分别用于赋值和取值
int* array_at(Array *a,int index){ return &(a->array[index]);}增长数组空间
void array_inflate(Array *a,int more_size){ int*p = (int*)malloc(sizeof((int)*(a->size+more_size));//定义缓存指针,申请more_size个内存空间 int i; for(i=0;i<a->size;i++){ p[i]=a->array[i];//将array原本的内存空间中的值赋给p } free(a->array);//释放内存空间 a->array = p;//将p值还原给a a->size += more_size;//增大a的size大小}不断写入数组内容

一直循环下去,总会出现数组越界的情况。
于是,继续修改array_at

引入block概念
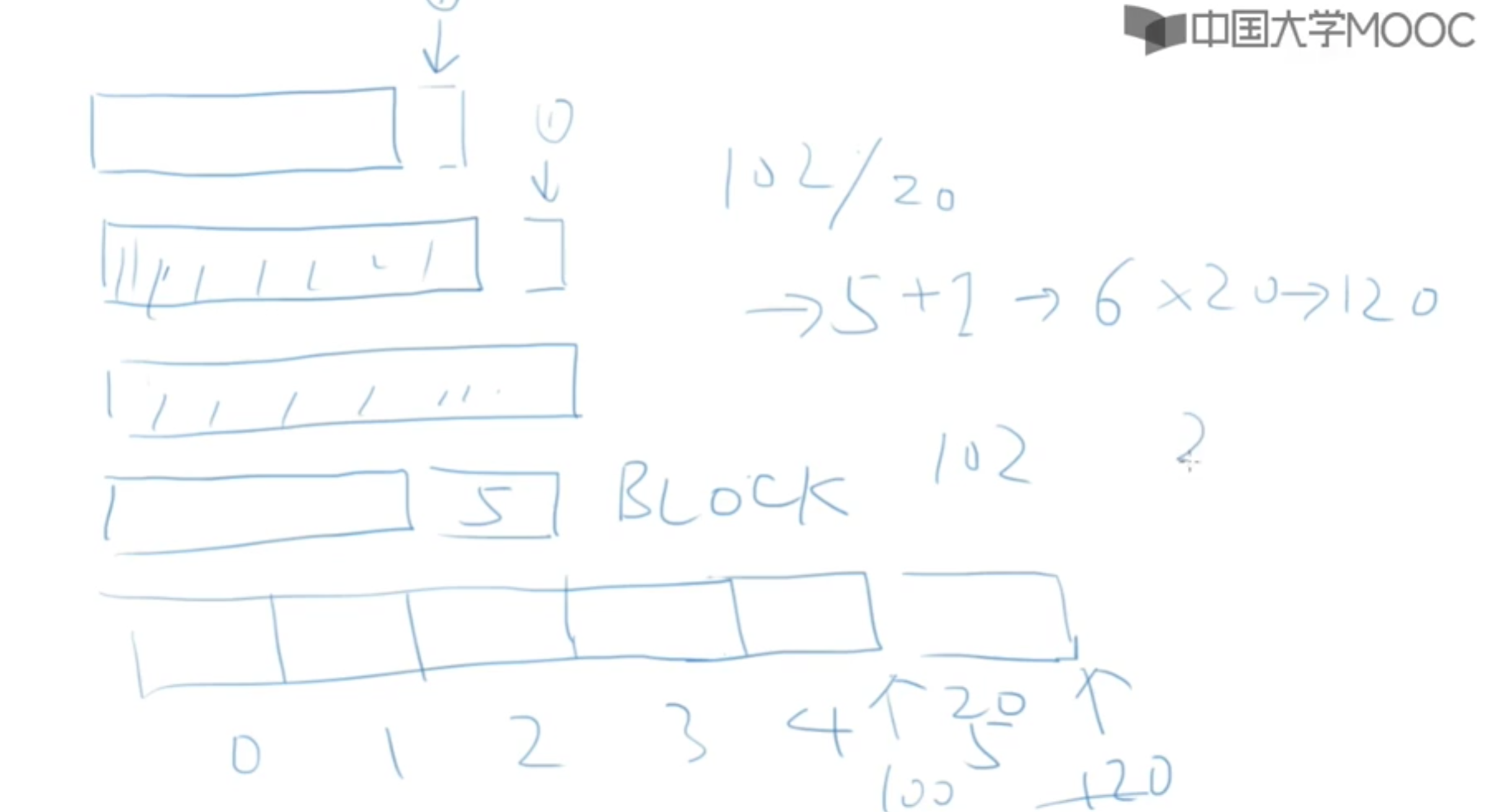
二、 可变数组的缺陷
- 拷贝时间开销大
- 在内存受限的情况下,可能难以申请到更大的内存空间
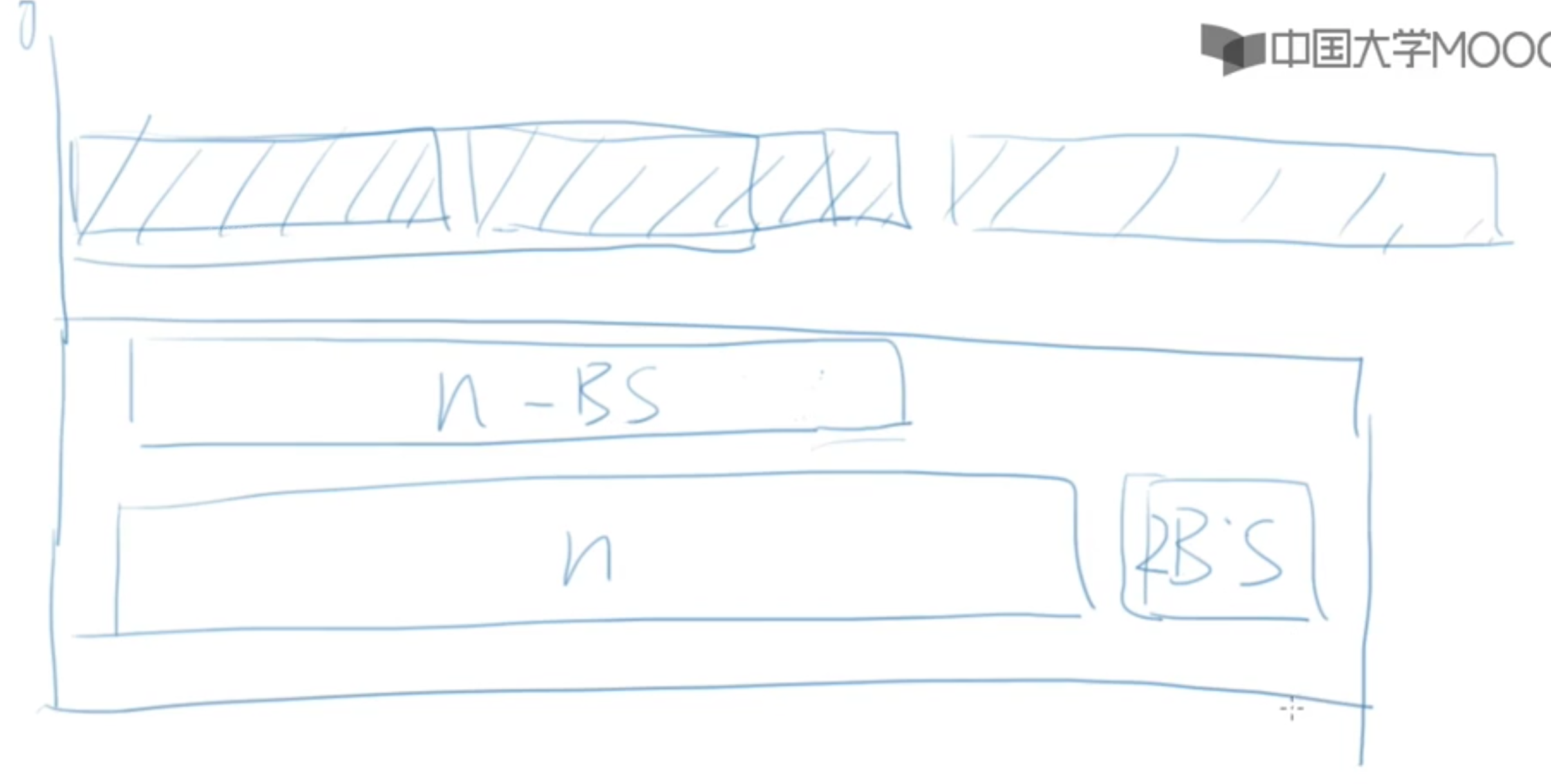
解决方案:
不去修改原来的内存空间,链接1个block即可拓展数组长度

三、链表
链表中的元素簇称为“节点”
每个节点仅包含两个部分:
- 数据
- 指向下一个节点的指针
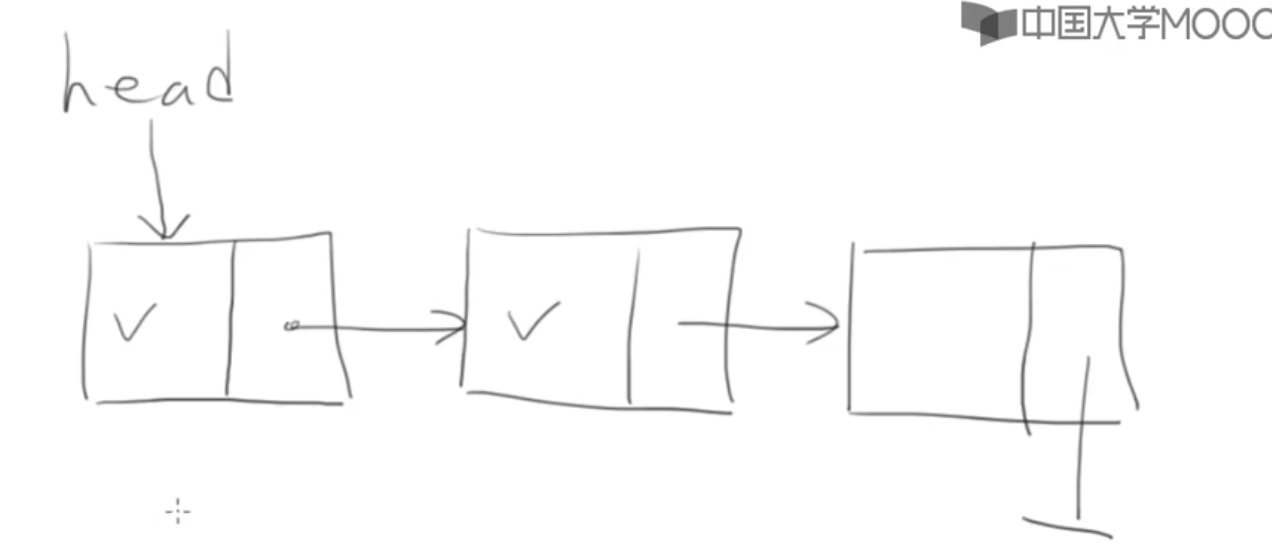
typedef struct _node{ int value; struct _node next;}Node;思考:为什么不用:
struct Node next;因为在这一行还没有执行Node的类型重定义,编译器无法识别。
使用struct _node{
}定义了struct _node类型的结构体
使用typedef … Node重定义了struct _node类型
程序:循环输入数字,如果为-1则退出,
1. 定义head
Node *head = Null;2.定义第一个节点
Node *p = (Node*)malloc(sizeof(Node));p->value = number;p->next = Null;3. 定义last
Node *last = head;while(last -> next){ last = last -> next;}last->next = p;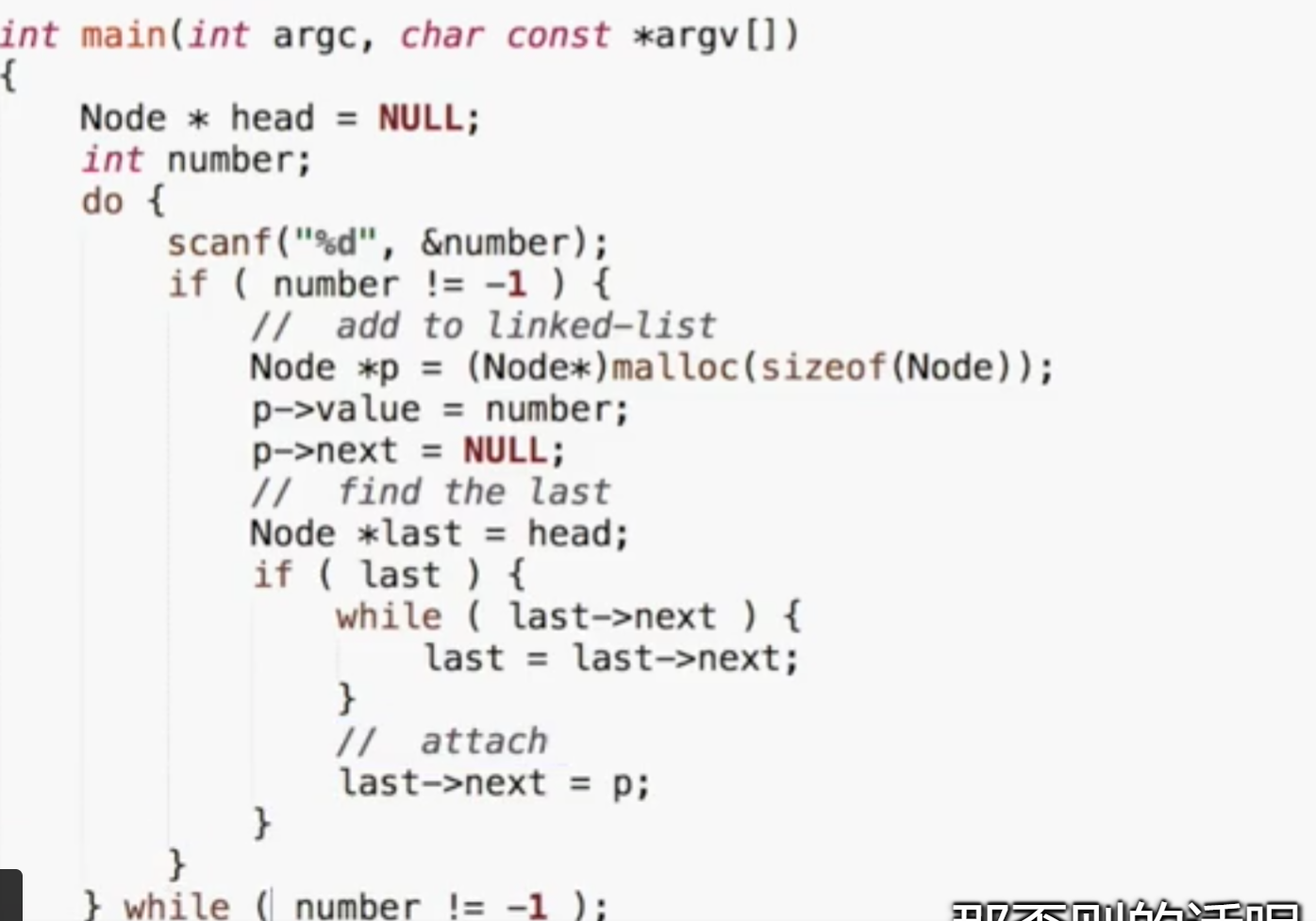
4. 链表函数——添加节点
实现一个创建节点的函数:
缺点:函数内部对head进行改变,但是并不影响外部的head(PS:这里的head为指针)
tips:尽量少用全局变量
void add(Node* head,int number){ //add to linked-list Node *p = (Node*)malloc(sizeof(Node)); p->value = number; p->next = NULL; //find the last Node *last = head; if(last){//如果last指向非空 while(last->next){//last的nest指向非空 last = last->next;//last等于last指向的next } // attach last->next = p;//last指向的next等于p }else{ head = p;//修改head }}| |
| |
/
修改程序
Node* add(Node* head,int number){ //add to linked-list Node *p = (Node*)malloc(sizeof(Node)); p->value = number; p->next = NULL; //find the last Node *last = head; if(last){//如果last指向非空 while(last->next){//last的nest指向非空 last = last->next;//last等于last指向的next } // attach last->next = p;//last指向的next等于p }else{ head = p;//修改head } return head; // <================= 将head返回出去}在主程序中,即可实现改变head的操作,但是这也存在一个缺点,如果忘记调用head = …,程序会报错,封装还不够完美
head = add(...);| |
| |
/
第三种方案,传head改为传递head的指针(实际上是指针的指针)
tips:数据结构
实际上,现在这个函数,return返回值,以及主程序中的赋值都可以不进行,提高了程序的易用性,根本原因是因为pHead是head的指针,即指针的指针
Node* add(Node** pHead,int number){ //add to linked-list Node *p = (Node*)malloc(sizeof(Node)); p->value = number; p->next = NULL; //find the last Node *last = *pHead; if(last){//如果last指向非空 while(last->next){//last的nest指向非空 last = last->next;//last等于last指向的next } // attach last->next = p;//last指向的next等于p }else{ *pHead = p;//修改head } return *pHead;}| |
| |
/
第四种方案 ,添加一个List类型结构体
typedef struct _list{ Node *head;}List;这样,函数可以改写为
void add(List *plist,int number){ //add to linked-list Node *p = (Node*)malloc(sizeof(Node)); p->value = number; p->next = NULL; //find the last Node *last = plist->head; if(last){//如果last指向非空 while(last->next){//last的nest指向非空 last = last->next;//last等于last指向的next } // attach last->next = p;//last指向的next等于p }else{ plist->head = p;//修改head }}思考:调用这个函数,last每次都要从head开始指向,执行了没有必要的操作,如何让函数执行完之后,last指向保持上一次的指向?
| |
| |
/
typedef struct _list{ Node *head; Node *tail;}List;
实现:
在 List 结构体中添加一个指向链表尾节点的指针 tail,然后每次添加节点时,直接更新 tail 的指向。这样可以避免每次都从头开始遍历链表,优化了插入操作的效率。
修改后的代码示例
- 修改
List结构体:添加一个tail指针,指向链表的最后一个节点。 - 修改
add函数:在每次添加新节点时,直接更新tail指针。
void add(List *plist,int number){ //add to linked-list Node *p = (Node*)malloc(sizeof(Node)); p->value = number; p->next = NULL; //find the last if(plist->tail){//如果尾节点存在 plist->tail->next = p;//尾节点的next指向新节点 }else{ plist->head = p;//头节点指向新节点 } plist->tail = p; // 更新 tail 为新添加的节点}这种方式通过维护一个指向尾节点的指针,可以避免每次添加节点都从头遍历,优化了链表操作的效率。
5. 链表函数——打印
void print(List *list){ Node *p; for(p=list->head;p;p=p->next){ printf("%d\t",p->value); printf("\n"); }}6. 链表函数——删除

7. 链表函数——清除
void clear(List *plist) { Node *current = plist->head; Node *nextNode;
while (current != NULL) { nextNode = current->next; // 保存下一个节点 free(current); // 释放当前节点 current = nextNode; // 移动到下一个节点 }
plist->head = NULL; // 清空头指针 plist->tail = NULL; // 清空尾指针}